
Introduction
This guide covers how to integrate Spring Boot, Spring Web, and Spring AI Tika Document Reader to build a RESTful application that extracts text from various document formats, such as PDF, DOCX, PPTX, and HTML. The application will allow users to upload documents and retrieve extracted text in a structured format.
Prerequisites
Before you begin, ensure you have the following:
- JDK 17 or later
- Maven
- Spring Boot 3.4.4
- Postman or cURL for API testing
Project Setup
1. Create a Spring Boot Project
You can generate a Spring Boot project using Spring Initializr with the following dependencies:
- Spring Web (for RESTful API)
- Tika Document Reader AI (for text extraction)
Alternatively, create the project manually with the pom.xml configuration below.
2. Configure pom.xml
Here is the pom.xml configuration for our project:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>3.4.4</version>
<relativePath/>
</parent>
<groupId>com.example</groupId>
<artifactId>document-reader</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>Document Reader</name>
<properties>
<java.version>17</java.version>
<spring-ai.version>1.0.0-M6</spring-ai.version>
</properties>
<dependencies>
<!-- Spring Web for REST API -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!-- Apache Tika Document Reader for text extraction -->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-tika-document-reader</artifactId>
</dependency>
<!-- Testing dependencies -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-bom</artifactId>
<version>${spring-ai.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
</project>Project Structure
A clean project structure for this application looks like:
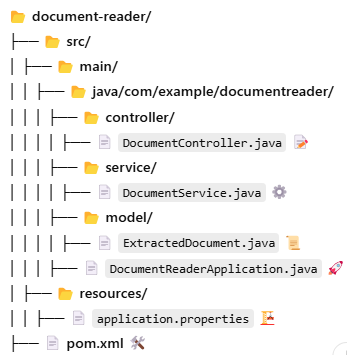
Implementation
1. Create the Model Class
package com.example.documentreader.model;
public class ExtractedDocument {
private String fileName;
private String content;
public ExtractedDocument(String fileName, String content) {
this.fileName = fileName;
this.content = content;
}
public String getFileName() {
return fileName;
}
public String getContent() {
return content;
}
}2. Create the Service Class
package com.example.documentreader.service;
import org.springframework.ai.document.Document;
import org.springframework.ai.tika.TikaDocumentReader;
import org.springframework.stereotype.Service;
import org.springframework.web.multipart.MultipartFile;
import java.io.IOException;
import java.util.List;
@Service
public class DocumentService {
private final TikaDocumentReader tikaDocumentReader;
public DocumentService(TikaDocumentReader tikaDocumentReader) {
this.tikaDocumentReader = tikaDocumentReader;
}
public String extractTextFromDocument(MultipartFile file) throws IOException {
List<Document> documents = tikaDocumentReader.read(file.getInputStream());
return documents.stream()
.map(Document::getContent)
.reduce("", (acc, text) -> acc + text + "\n");
}
}3. Create the Controller Class
package com.example.documentreader.controller;
import com.example.documentreader.model.ExtractedDocument;
import com.example.documentreader.service.DocumentService;
import org.springframework.http.ResponseEntity;
import org.springframework.web.bind.annotation.*;
import org.springframework.web.multipart.MultipartFile;
import java.io.IOException;
@RestController
@RequestMapping("/api/documents")
public class DocumentController {
private final DocumentService documentService;
public DocumentController(DocumentService documentService) {
this.documentService = documentService;
}
@PostMapping("/upload")
public ResponseEntity<ExtractedDocument> uploadDocument(@RequestParam("file") MultipartFile file) {
try {
String extractedText = documentService.extractTextFromDocument(file);
ExtractedDocument extractedDocument = new ExtractedDocument(file.getOriginalFilename(), extractedText);
return ResponseEntity.ok(extractedDocument);
} catch (IOException e) {
return ResponseEntity.internalServerError().build();
}
}
}Testing the API
1. Running the Application
Run the application using:
mvn spring-boot:run2. Uploading a Document via Postman or cURL
Postman
- Open Postman.
- Set method to POST.
- Enter URL:
http://localhost:8080/api/documents/upload - Select Body → form-data.
- Add a key named file, set it to File, and upload a document (PDF, DOCX, etc.).
- Click Send.
cURL
curl -X POST -F "file=@/path/to/document.pdf" http://localhost:8080/api/documents/uploadExpected Response (JSON)
{
"fileName": "document.pdf",
"content": "Extracted text from the document..."
}Unit Testing
Create a test class DocumentServiceTest.java:
package com.example.documentreader.service;
import org.junit.jupiter.api.Test;
import org.mockito.Mockito;
import org.springframework.ai.tika.TikaDocumentReader;
import org.springframework.web.multipart.MultipartFile;
import static org.junit.jupiter.api.Assertions.assertNotNull;
import static org.mockito.Mockito.mock;
class DocumentServiceTest {
@Test
void testExtractTextFromDocument() throws Exception {
TikaDocumentReader reader = mock(TikaDocumentReader.class);
DocumentService service = new DocumentService(reader);
MultipartFile mockFile = mock(MultipartFile.class);
assertNotNull(service.extractTextFromDocument(mockFile));
}
}Conclusion
This guide demonstrated how to build a Spring Boot REST API with Spring Web and Spring AI Tika Document Reader for document text extraction. You can now expand this project by adding authentication, database storage, or additional AI-based processing.
📄 Document Reader AI with Spring Boot
Build a powerful document reader using Spring Boot and Apache Tika for AI-powered text extraction.
📂 Clone on GitHub